
Reliability Through Immutability: Killing CI Drift at the Pool Level
How a mid-market firmware program stopped inconsistent test results across a 150-runner fleet
TL;DR
- Drift is the silent CI killer ("works on one runner, fails on another").
- Our stance: immutability by default at the pool level — change the spec → the whole pool is rebuilt. No in-place edits. MartinFowler.com
- This cuts toil and stabilizes results. Google SRE
- Same developer experience in cloud or on-prem — including air-gapped with offline bundles/mirrors. Air-gapped CI
Treat runners as cattle not pets: replace, don't patch. cloudscaling.com
Bake-then-replace is a proven pattern at scale. Netflix TechBlog
Why drift keeps biting teams
CI doesn't usually fail because your code "hates you." It fails because environments quietly diverge:
- Someone "just fixes" one box.
- A minor version lands on half the fleet.
- PATH/registry, license clients, or drivers differ by host.
Golden images and scripts slow drift; they don't prevent it. As long as a system allows edits on live hosts, drift is a feature, not a bug.
Immutable infrastructure flips the behavior: you replace, you don't patch — an idea popularized by MartinFowler.com's Immutable Server and Phoenix patterns. Immutable Server · Configuration Synchronization
The real case: firmware CI that wouldn't agree with itself
Context. A mid-market firmware program (25 engineers) ran ~1.8k CI jobs/day on 150 runners across Linux and Windows. Toolchains included GCC/Clang, a Python test harness, vendor SDKs, and (on Windows) license clients and USB driver stacks.
Pain. The same commit produced different performance outputs depending on which runner executed the tests. In some weeks, ~11% of jobs flagged outliers or failed due to environment differences — not code defects.
Typical culprits we found.
- Windows runners with ad-hoc
PATH/registry tweaks for debugging. - Linux runners drifting
numpy/scipyvia unattended updates → numeric differences. - License client patches toggling compiler flags.
- CPU governor policy changes skewing latency/power on HIL tests.
What didn't work. Golden images/hardening scripts slowed decay, but any manual "temporary tweak" reintroduced variance.
Decision. Move to pool-level immutability: change the definition (OS, versions, roles) and the entire pool is replaced from a known image; no SSH, no "fix that one box." This mirrors bake-then-replace discipline proven at Netflix. How We Build Code at Netflix
Architecture at a glance
Declare → Reconcile → Replace. Define a Pool (OS, size, roles/toolchains, CI connector). Orchestrator compares desired vs actual and rotates nodes to the new spec — no in-place changes.
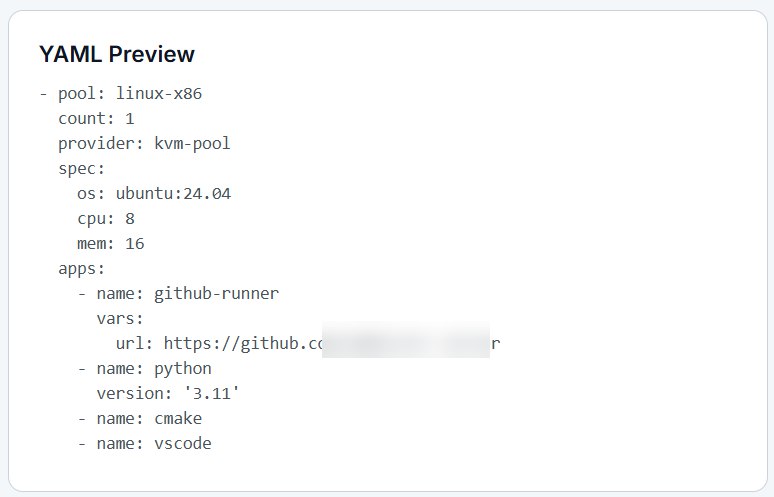
[Pool Definition]
OS: linux | windows | macos
Size: N
Roles: [python-3.11, cmake, vscode, blackduck, ...]
CI: jenkins-agent | github-runner
↓ reconcile
[Provisioner] builds image/artifacts for spec
[Pool Rebuilder] atomically replaces nodes to match spec
[CI Connectors] agents/runners auto-register to Jenkins/GitHub- Roles (packs): versioned toolchains you attach to pools.
- Rebuilder: spec change → replacement, not mutation.
- Drift posture: out-of-band edits are overwritten at next reconcile.
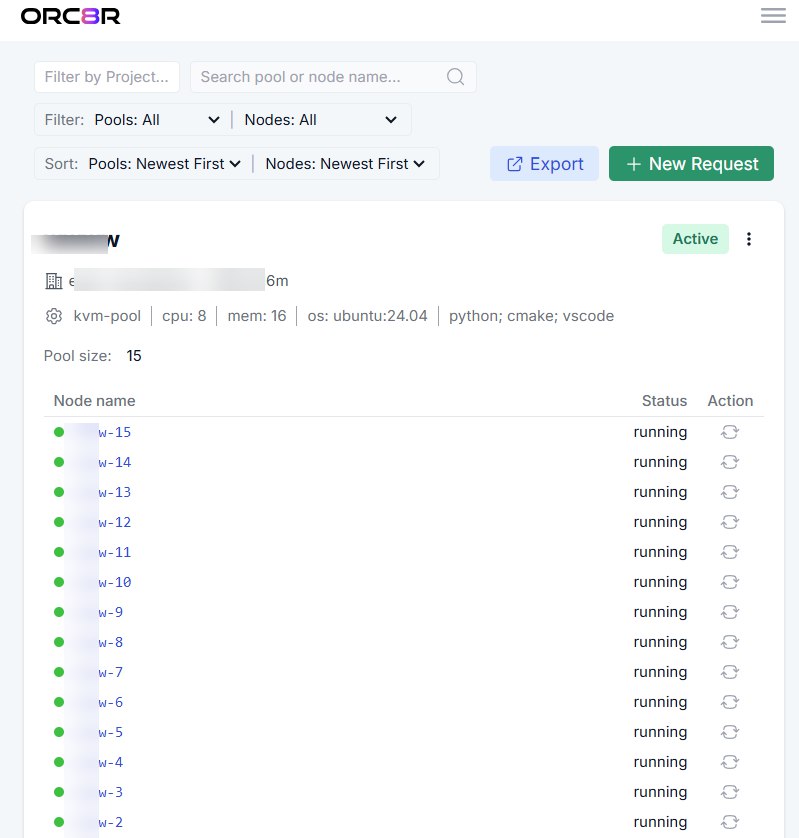
A narrow, high-signal walkthrough
Change: bump Python & wheels across 90 Linux runners (Python 3.10→3.11, numpy 1.25→1.26).
pool update linux-perf-ci --roles=python-3.11,numpy-1.26.0,clang-16,...
pool apply linux-perf-ci09:42:03 spec.update pool=linux-perf-ci diff=python:3.10→3.11 numpy:1.25→1.26
09:42:04 build.image roles=[python-3.11,numpy-1.26,...] sha=sha256:af2c...
09:42:32 drain.node node=lin-081 status=quiescing jobs=0
09:42:34 create.node node=lin-151 image=linux-perf-ci@sha256:af2c...
09:42:57 register.ci node=lin-151 ci=jenkins agent_id=JNK-5141
...
09:48:11 pool.healthy pool=linux-perf-ci nodes=90 spec=sha256:af2c...Isn't this what the industry already does?
Others vs. Orchestrator (quick read)
- Docker / Kubernetes / Nomad: images/pods can be immutable, but host drift is common; ConfigMaps/Secrets mutate; "identical runner pools" aren't enforced by default.
- GitHub Actions Runner Scale Sets / ARC: great for ephemeral runners and autoscaling, but image/version hygiene is on you; there's no built-in "change spec → replace all runners" mandate. Runner scale sets · ARC
- Spinnaker/AMI bakery: proven deploy parallel — bake then replace fleets. We apply the same philosophy to CI runners. Netflix · InfoQ summary
- Orchestrator: pool-level replace by default + a roles layer + mixed OS (incl. macOS).
What changed (numbers that matter)
| KPI | Before | After |
|---|---|---|
| Env-mismatch failures / 1,000 jobs | 118 | 9 (-92.4%) |
| Performance variance (p95 across runs) | ±7.3% | ±0.6% |
| Toolchain rollout (spec → healthy pool) | ~2 days | 18–24 min |
| Rollback to prior spec | ~4 hours | 11 min |
Why this holds: immutable servers are replaced, not patched; bake-then-replace stabilizes fleets. Fowler · Netflix
Trade-offs & failure modes
- Strict by design: need a quick fix? Change the spec; no hot-patching nodes. Immutable Server
- State: runners must be stateless; artifacts/caches live in registries or buckets.
- Rotation windows: we drain first; plan headroom for large rollouts.
Cloud, on-prem, air-gapped: same experience
Some teams can't allow internet egress. The experience should still be the same:
- On-prem connected: pull roles/images via proxy; standard SSO/webhooks.
- Air-gapped: import signed offline bundles, mirror packages/containers internally, keep logs/monitoring inside the boundary. Guide
Minimal hands-on (try it like an architect)
- Create a 5-node pool (Linux/Windows/macOS) and attach
python-3.11,cmake. - Run real jobs for a day; note env-mismatch failures.
- Change one role version; watch the rotation log as the pool replaces to the new spec.
- Measure the 3 KPIs above.
References
- MartinFowler.com — Immutable Server: martinfowler.com/bliki/ImmutableServer
- MartinFowler.com — Configuration Synchronization/Phoenix: martinfowler.com/bliki/ConfigurationSynchronization
- Google SRE — Eliminating Toil: sre.google/sre-book/eliminating-toil
- cloudscaling.com — Pets vs Cattle: cloudscaling.com/.../pets-vs-cattle
- Netflix — How We Build Code: techblog.netflix.com/.../how-we-build-code
- InfoQ — Netflix AMI Bakery: infoq.com/news/2016/03/How-Netflix-Builds-Code
- GitHub — Runner Scale Sets: docs.github.com/.../runner-scale-sets
- GitHub — Actions Runner Controller (ARC): docs.github.com/.../actions-runner-controller
- Air-gapped CI — Offline bundles & mirrors: improwised.com/blog/ci-cd-in-air-gapped-environments
